Published April 22, 2024
Having the same content twice within your website is not ideal, and it can even be penalizing. It’s even worse when another site has the same content as yours. But you can fix it. Here’s how.
The amount of content on the internet is growing at a breathtaking rate. But the online population isn’t growing as strongly as in the early days of the internet, and the time users spend online may have peaked as well.
There are only so many hours in a day. There is more content but the same number of users. Maybe that is why attention spans are reducing: We are suffering from information overload.
The good news is that not all the information is new content, as some of it is duplicated. Or maybe that isn’t good news at all.
Overview: What is duplicate content in SEO?
Duplicate content occurs when identical core content appears on two different URLs. When a search engine runs into two nearly identical pieces of content, it will decide which version becomes visible. This can be problematic if you create content to generate website traffic and visitors end up on the wrong page. Especially if that page is not on your own domain, or if country-specific legal requirements apply to one of the URLs.
But you may be wondering if duplicate content hurts SEO. There is not a Google duplicate penalty as such when you have several copies of one piece of content. But its existence can penalize the indexing of your website.
Search engines do not crawl all the pages on a website. They stop when they estimate that all the important content has been found. This is often referred to as a "crawl budget." If you spend all your crawl budget on duplicate content, you risk other content not being indexed at all.
There are four ways of addressing duplicate content issues:
- Suppress one of the versions
- Redirect the less important version to the primary content
- Disallow indexation of lesser versions of the content
- Use canonical tags to point to the primary content
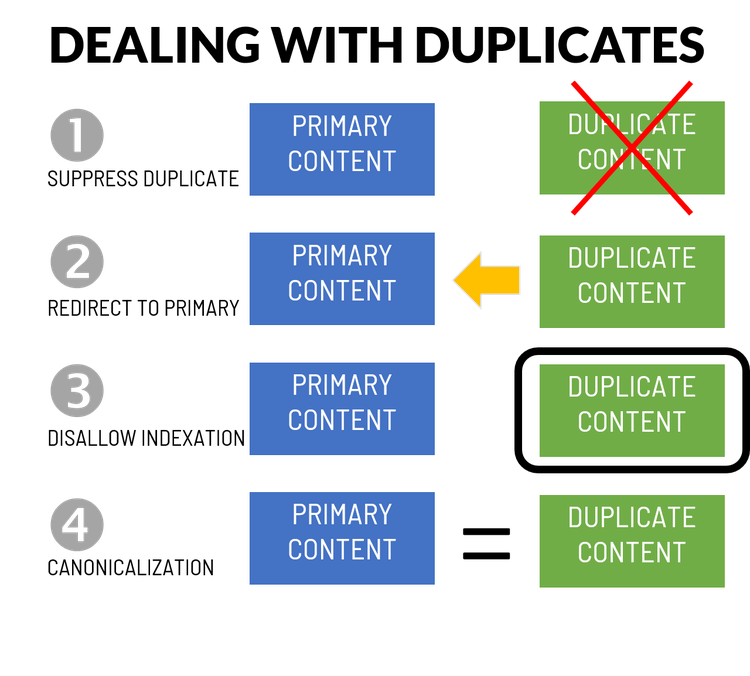
Of the four ways of dealing with duplicates, canonicalization is often the preferred method, but your choice depends on the type of duplication you encounter. Image source: Author
How does duplicate content happen?
Duplicate content SEO problems arise in surprising ways. Sometimes they are caused by inadvertence, other times by ignorance of SEO best practices. Fraud and plagiarism are very real causes too. Let’s look at some of the common errors you may encounter.
1. When you build your site on a dev.domain
A common practice in web development is to place a website under development on a subdomain. It can be called dev.yourdomain.com or newsite.yourdomain.com or something else. Users who don’t know the specific URL won’t be able to find it. Neither will search engine crawlers.
Unfortunately, it only takes one tiny little link pointing to any page in that new site from a public page for search engines to detect the site. And if one page is crawled, all the other pages of the site under construction will be crawled and indexed too. That’s no fun at all, so remember to keep password protection on all your sites during development.
2. When your domain configuration is not rigorous
Another common mistake is to configure your DNS entry (the way your domain name is configured) and your SSL certificate (the secure server certificate activating https) loosely. If you are not careful, you can end up with four versions of your site available to be indexed:
- http://www.yourdomain.com
- https://www.yourdomain.com
- http://yourdomain.com
- https://yourdomain.com
Again, one little link to the wrong version of your site can cause search engines to see double and index your contents twice -- or worse, index some pages from one version and some from another. Make sure you redirect the http version to https, and make sure the version of your domain you don’t wish to use redirects to your primary URL.
An additional configuration exists for default pages in a directory. In reality, the name of the file representing your homepage may be index.html or index.php, but best practice is to show only the name of the directory. If the configuration and the internal linking aren’t consistent, you could end up with several URLs indexed for the same page.
3. When your CMS has too many facets
Most sites are developed and managed using a content management system (CMS). And e-commerce sites often use store builders, which are similar to a CMS.
A common functionality for a product catalogue is to allow for multiple options for a product page. This could be to change the color or size of a product. For each changed option, the URL of the page adds parameters creating new URLs, all of which can be indexed by a search engine.
The same type of challenge exists in practically every CMS. If a CMS creates URLs on the fly, it is important to use canonical tags on the main page. A canonical tag will simply indicate which URL corresponds to the primary page. How a CMS manages SEO is very different from one solution to the next.
4. When scrapers steal your content
Scrapers are software robots that copy your page into a database. They “scrape” the information off the page. They are actually very similar to search engine crawlers and can be fully automated. Scrapers will typically analyze a destination site to identify where the content is situated, and then automatically scrape the content when a new page updates.
In most cases, scrapers are harmless. They are trying to enrich their site with content but rarely manage to rank for keywords related to it because search engines downrate the duplicate copy.
It can be problematic for you if the copying site has a high domain strength because it could outrank your original content in some cases. Often these sites will even maintain the original links in the content linking back to your domain, which increases the number of links pointing to your site.
In some cases, entire sites are copied and republished on other domains, sometimes changing the content slightly, inserting links to affiliate sites and hoping they get indexed. It is like email spam: When it is automated and has enough volume, the sum of all the small pieces of stolen value are higher than the cost of running the scam.
If your content has been stolen, you can try to find the site owner and take legal action or at least send a cease and desist letter. Most sites, however, won’t allow you to find the owner. You can also notify search engines under the Digital Millennium Copyright Act and ask for removal of the infringing page. Google has a legal troubleshooter process you can use for that purpose.
5. When you manage multinational sites
Duplicate content can easily appear when you manage a multinational site. Languages don’t perfectly overlay with countries.
Even if you have only an English-language version of your site, you may have domains for individual English-speaking countries around the world: the United Kingdom, Australia, South Africa. If you have a French version of your site, perhaps you want to use the same content in Canada, France, Belgium, and Switzerland.
To solve this complex puzzle of languages and countries, you may imagine the canonical tag could be used to refer to one single version of the content. However, a much better solution exists in the form of the “hreflang” tag.
The hreflang tag (or set of tags, allows you to indicate the corresponding country and language combination for all your content. In this way, search engines will know what version of a piece of content should go into each of their country databases, and duplication will be avoided.
6. When plagiarism is provided as content
The final type of duplicate content arises from plagiarism, wherein content writers are reusing their own or other writers’ content. All plagiarism can’t be detected, but happily there are many available tools to quickly and efficiently check for this, like the free plagiarism checker from Grammarly.
How do search engines determine duplicate content?
Search engines crawl URLs first and content second. They open doors to see what is behind them, and copy everything in there, then reduce it to a shorter form. In the shorter form, they strip away things like navigation menus and footers. This content is then compared with the existing content in their databases to identify similar content.
If the similarity is too high, the search engine will cluster URLs from the same domain together and only retain one URL. For similar content on different domains, it typically picks the older version. Hopefully, yours was indexed first.
How to avoid having duplicate content on your website
The SEO audit steps below are used for analyzing the architecture of a website.
1. Check and correct your domain setup
Search for your domain name in Google (without the preceding www’s) to identify what versions of the domain and its subdomains are indexed. You can also find subdomain finder tools like the one below to see what they can find from DNS records.

Subdomain Finder is a quick and efficient way to see all the configured subdomains to check for duplicate content. You can then search for each of them to see what content is indexed. Image source: Author
Source: subdomainfinder.c99.nl.
2. Check for plagiarism and retaliate
Is someone scraping and republishing your content under their own name? For a specific page with a unique title, check this by entering the exact title into Google to see if other pages appear for that search. You can immediately spot any plagiarism.
A broader approach is to use a duplicate content checker such as Copyscape, a tool that will scrape your URL and identify near-duplicates on other URLs.

Copyscape found three duplicates of an article published on the PPC Hero blog. The blog is scraped selectively and content is republished on other sites. Image source: Author
Source: copyscape.com.
3. Check for URL duplications and repeated content
You checked your domain and Google duplicate content on other domains as well. Now it is time to dig into your own site to check for URL duplications and repeated content. To do this, you need to crawl your website as if you were a search engine crawler.
This is one of the specialties of some of the leading SEO tools in the market, and there are also stand-alone tools, such as Screaming Frog and Xenu Link Sleuth, which can perform a crawl for you.
A nifty tool to check the most common inconsistencies is a tool built by SEOs.

The five duplicate content verifications the tool runs correspond to some of the most common mistakes and is a good starting point. Image source: Author
Source: hivedigital.com/free-tools/duplicate-content/.
A cleaner and leaner site is better for SEO
To avoid duplicate content, you must be careful with subdomains and access control during web development. When you launch, you should make sure only the primary version of the site is visible, and that all other versions redirect to that one. You can use canonicalization to avoid many CMS challenges in larger sites, and you can use hreflang tags to get your international site versions right.
If you are facing copycats, you can try to remove their content. All of this will make your site leaner and cleaner. It will allow for a wider variety of content to be indexed and help the right content surface. If your site was affected by duplicates, it can have a great impact on your SEO.
Our Small Business Expert
Anders Hjorth is the author of four digital marketing insights reports and the founder of Innovell, a Digital Marketing consultancy researching trends in digital marketing. As a pioneer in SEO, one of the first Google Advertising Professionals, and the co-founder of several agencies, he has broad and long-running experience across SEO, paid search, social media, and content marketing. Anders was COO for GroupM Search across EMEA. Anders is also an active member of various awards juries and advisory boards including the Paid Search Association.
Share This Page
We're firm believers in the Golden Rule, which is why editorial opinions are ours alone and have not been previously reviewed, approved, or endorsed by included advertisers. The Ascent does not cover all offers on the market. Editorial content from The Ascent is separate from The Motley Fool editorial content and is created by a different analyst team.
The Motley Fool has a disclosure policy.