Published April 22, 2024
Robots.txt can greatly impact your SEO, especially if it is used wrongly. Find the best practice and the detailed instructions here.
Think of a road sign: Dead End Street. Max 55 MPH. No Parking. What if you could take all those instructions and put them into a file that your car could read and understand? Surely, a step on the way to self-driving cars.
The robots protocol and the famous robots.txt file that most websites have is exactly that. Not for cars on roads, but for search engine crawlers on websites.
Overview: What is robots.txt?
The robots.txt file is one of the few ways you can give instructions to search engines on how to interpret your website. It is an instrument the search engines created to make it easier to provide crawling instructions and also to avoid damage to websites from over-intensive crawling.
When a search engine crawler first visits a website, it will look for the robots.txt at a specific location. If the file is correctly configured, the crawler will read the instructions in the file indicating which URLs it is allowed to crawl, and which URLs are disallowed.

Technical SEO addresses server-related, page-related, and crawler issues. Image source: Author
In practice, providing the right instructions to crawlers can seem pretty simple, but you would be surprised how often wrongly configured robots protocols cause SEO problems.
Is your robots.txt configured for SEO disaster?
Before going any further, let's check if you potentially have an issue with the robots protocol for your website. If you have set up a Google Search Console, you can check your robots.txt file via this robots testing tool.
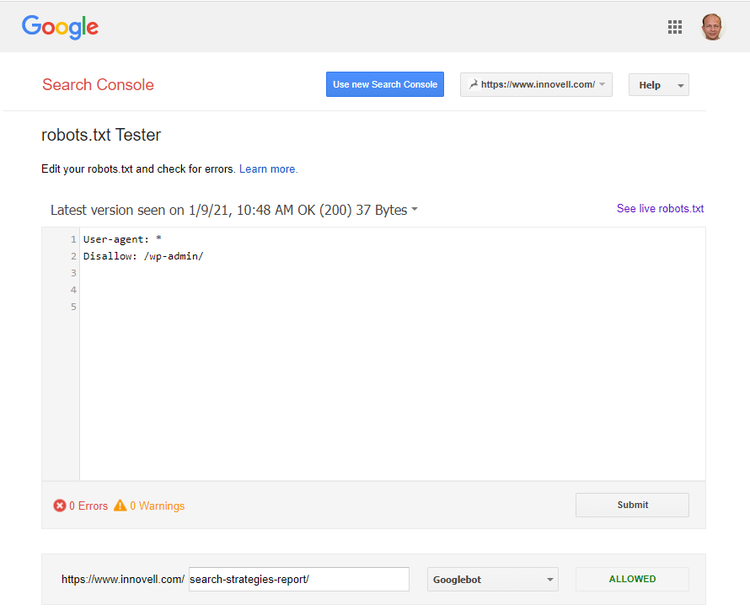
You can access the robots.txt checker from the Coverage section of Search Console but also access it directly to check that Google reads the file correctly, and check what is in it. Image source: Author
Source: https://www.google.com/webmasters/tools/robots-testing-tool.
If you don't have a search console account -- yet -- then let's check the file the manual way. Put your own domain name into this URL to see the file: https://www.domain.com/robots.txt.
You may be in trouble if you see only two lines looking like the robots.txt example below:
user-agent: *
disallow: /
Then you are giving full disallow instructions to all crawlers. This means none of your site's pages will be indexed. This is great if the site is under development; it is a disaster if it is launched and you were hoping to rank in search engines.
If you are now in panic, don't hesitate to simply delete the file from your server. Or read on to fully understand the role of robots.txt for your SEO.
What is the robots.txt file for?
The robots protocol is open for all crawlers. You can use it to allow or disallow access to content on your website selectively to certain bots, and selectively to certain parts of your website.
It is common practice to use robots.txt mainly to disallow access to those crawlers or bots that you don't wish your content to be shared with and to disallow those parts of the website that shouldn't be shared widely.
A robots.txt can work hand in hand with a search engine sitemap submitted via webmaster tools to guide crawlers to pages that are important for your SEO.
How does your robots.txt file impact SEO?
The role of robots.txt belongs in the area of technical SEO alongside other optimizations of the architecture of your website and your internal linking. It can be used at key times in your SEO efforts in the following ways.
Robots.txt helps you avoid indexing unfinished sites
Search engine crawlers are unlikely to find the URL of an unfinished website, but there is no guarantee. Robots.txt instructions provide that guarantee by providing clear instructions to search engines on what they are allowed to visit.
Robots.txt can help manage your crawl budget
If you are performing an SEO audit, the role of robots.txt will be related to the concept of a crawl budget. For each individual website, search engines allot a certain amount of attention. If that attention budget is spent on indexing insignificant pages, you risk not having pages important for your SEO indexed.
You can guarantee indexation of your key pages by disallowing access to parts of a website carrying no SEO value because of the nature or the format of the content. With an optimized crawl budget, you increase your chances of ranking in search engines.
How to properly set up your robots.txt
The robots protocol is very precise. If your file is not formatted correctly or placed in the wrong place or has the wrong name, its instructions will be ignored by crawlers.
1. Use the right file format
The robots.txt file is a simple text file. The expected file encoding is the UTF-8 format.
2. Use the right file URL
Crawlers will look for the file at the root directory of a domain. It should be available for any domain which is accessed. You need to carefully consider how the physical file can be accessed via multiple formats of the URL.
A domain can often be accessed via http and https and both by using www or not in front of the domain name itself. The instructions in the resulting robots.txt need to be consistent with the URL on which it is seen.
3. Use the right file name
You probably know that one by now.
Needless to say, if the file has another name it won't be read. You can keep working copies of other robots files and call them robots.old or robots2020.txt with no risk of them being read.
Providing the wrong name or not having a file at all effectively works like having a robots.txt allow all instruction.
3 robots.txt best practices
The best way to set up your robots.txt file really depends on where in the website process you are. Is your site under development? Is it up and running? Does it have indexation problems? Let's look at the ideal set up for your robots.txt below.
1. Disallow any temporary domains or subdomains
Whenever you open a new domain or subdomain in a temporary manner, you should create a robots.txt disallow file before placing any pages there. In that way, you are sure no information appears in search results by mistake.
2. Do an SEO crawl before removing disallow instructions
Before you open your site to search engine crawlers, you can simulate their visit using an SEO crawler which you instruct to ignore the robots.txt instructions.
When you are sure the site works as expected, you can remove the disallow instructions.
3. Don't use robots.txt retroactively
There is no such thing as a robots.txt no index instruction. It is either crawl or don't crawl. But what happens if a page was already crawled by error?
To remove the page from the index, the best way is to delete it and wait for the search engines to recrawl the URL to find a 404 error code. This will prompt the search engine to remove the page from its index. Only then can you provide a robots.txt disallow instruction for the page and put it back on your server.
If you disallow access to a page that is already indexed, the search engines are not allowed to revisit the page but may keep the page in the index.
Be in charge of crawler activity
Taking control of the timing and the extent to which your website's content is crawled by search engines is the best way to get fast and optimal SEO results. Unfortunately, if you have made a misstep in the process, it can be difficult and time-consuming to correct the resulting wrong indexation.
The two keys to optimally using robots.txt is to have it in place from the start with disallow instructions, and know when to allow crawlers to access the content of your website.
Our Small Business Expert
Anders Hjorth is the author of four digital marketing insights reports and the founder of Innovell, a Digital Marketing consultancy researching trends in digital marketing. As a pioneer in SEO, one of the first Google Advertising Professionals, and the co-founder of several agencies, he has broad and long-running experience across SEO, paid search, social media, and content marketing. Anders was COO for GroupM Search across EMEA. Anders is also an active member of various awards juries and advisory boards including the Paid Search Association.
Share This Page
We're firm believers in the Golden Rule, which is why editorial opinions are ours alone and have not been previously reviewed, approved, or endorsed by included advertisers. The Ascent does not cover all offers on the market. Editorial content from The Ascent is separate from The Motley Fool editorial content and is created by a different analyst team.
The Motley Fool has a disclosure policy.