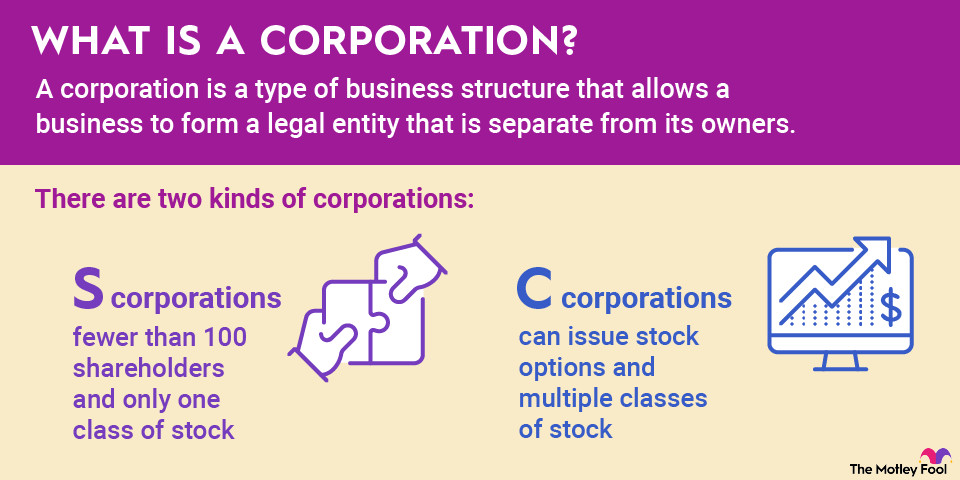
Loading paragraph...
Loading image...
Loading paragraph...
Loading definition...
Loading paragraph...
Loading paragraph...
Loading hub_pages...
Loading paragraph...
About the Author

Kristi Waterworth has been a contributing real estate and financial expert at The Motley Fool, covering real estate, investing, and personal finance topics, since 2020. Kristi has been interviewed by various TV media outlets and podcasts for her real estate investing expertise – from residential real estate to digital real estate and everything in between. Kristi’s journalist career spans over 25 years, and she has written about real estate investing, homeownership, and home construction specifically for the last decade. She was also previously a licensed Realtor and general building contractor before the Great Recession and housing market collapse. She holds a bachelor’s degree in American history from Columbia College in Missouri.
The Motley Fool has a disclosure policy.